ML Tutorial: Weka Part 1 – Feature Selection
This three part series uses Weka to:
Part 1: Perform Feature Selection
Part 2: Predict Sales Volume using k-NN
Part 3: Predict Sales Volume using a Support Vector Machine
Getting started
Weka is an easy to use application for discovering machine learning. It is a great place to start. It’s free, provides a large number of learning algorithms, and uses a GUI that makes fine tuning your machine learning results easy.

Installing Weka
There are two different types of Weka downloads. If your machine already has java running, you can install just Weka by itself. Otherwise you can download and install them both together at one time. Lets run it to see its opening screen.
Data for this tutorial
The objective of this tutorial is to see machine learning in action in the the context of a simple to understand business scenario. Here, the business wants us to predict profits for a list of new products.
The business provides us two lists: 1. products already being sold, and 2. new products being considered. The arff files are preformatted for use in Weka. You may feel more comfortable reviewing the data in the Excel file which contains both lists. You can download the data used in these tutorials here.
Feature Selection: is all the data important?
This data contains 22 features, or attributes, for each product. The 23rd attribute is the Sales Volume. In this scenario the sales volume is the attribute we want to predict for the new products so we refer to that as the classifier. The first question we might want to ask is: do all of these attributes equally impact sales? Is the type of Shipment as important as the number of 5 Star Reviews?
Feature selection is the process of finding a subset of attributes that can be used for the best possible outcome of the learning algorithm. Attributes that contain redundant or irrelevant data can mislead, overwhelm the calculations, and even produce false results.
Overfitting is another side effect of redundant attributes. Overfitting, in a sense, is tricking the trainer of the model into training too well. An overfitted trained model fits the training data perfectly but does not do very well when new data is introduced. It tends to incorrectly misclassify new instances making the over-fitted trained model somewhat useless.
Let’s start by opening a file in Weka.
In Weka
- Start Weka
- Select Explorer
- Click: Open File
- Choose existing_product_attributes.arff
- Click: Open
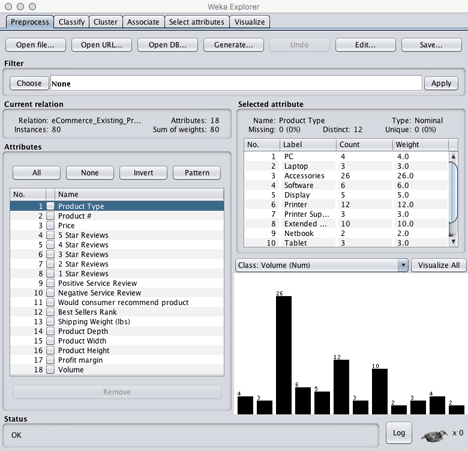
If you click Edit you will see a sheet of data that can be edited by clicking on a cell. If you wish you can even add an entire new instance (row). For now lets not change anything and click Cancel.
In the Attributes section we a list of all the attributes. We will modify this list after we determine which attributes we want to work with. First, let’s get Weka’s advice about which attributes are the most important.
In Weka
- Click the Select attributes tab
Notice two buttons: Attribute Evaluator and Search Method.
The Attribute Evaluator is the process Weka uses to evaluate each attribute in the context of our classifier: Sales Volume. Evaluation is done using a correlation-based algorithm. The Search Method finds the best subset using a random and exhaustive algorithm and ends by ranking individual attributes.
An attribute subset is considered good if it is highly correlated to the class and none of the members are correlated with each other. There are multiple choices in Weka’s menu and as we will see some of the evaluators only work with certain search methods. Some only work with nominal classes. In our case since sales volume is numeric some of the menu choices will not work.
Lets start with one combination.
In Weka
- Under Attribute Evaluator choose CfsSubsetEval
- Click Close
- Under Search Method choose GreedyStepwise
- Click Start
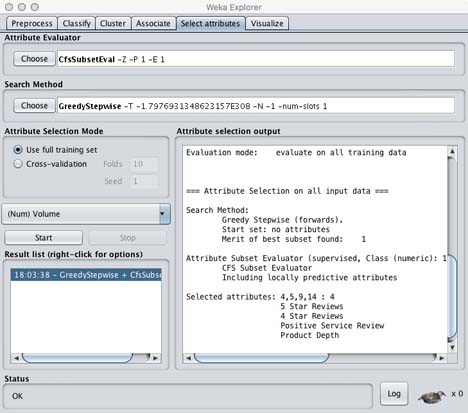
Attribute Evaluator: CfsSubsetEval; Search Method GreedyStepwise
Here we see that the best attributes are 5 Star Reviews, 4 Star Reviews, Positive Service Review and Product Depth.
Weka can be an excellent mentor when trying to learn concepts in machine learning. For example, suppose we chose CfsSubsetEval with a search method: Ranker. Weka throws an error.
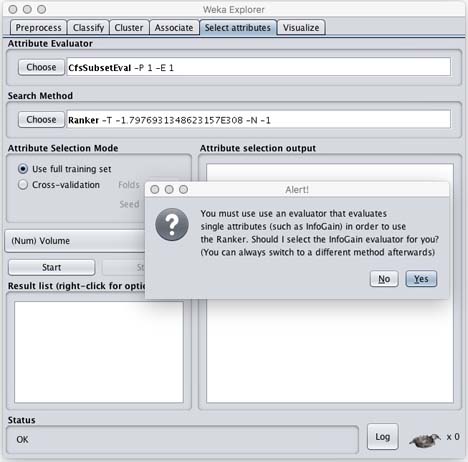
Once we learn what is not possible, Weka makes it easy to compare different algorithms by quickly making new menu choices and running a new combination of algorithms. If we run two other possible combinations of algorithms we get these results.

Running these three algorithms we see the following three attributes were found by each algorithms: 5 Star Reviews, 4 Star Reviews, Positive Service Reviews. We decide to prune the data set to contain just these attributes.
Remove attributes in existing products file
Using Weka we can easily remove unwanted features.
In Weka
- Select Preprocess
- Place a check mark next to all the attributes except: Product #, 5 Star Reviews, 4 Star Reviews, Positive Service Review, and Negative Service Review, and Volume
- Click: Remove
- Click Save with the name existing_product_attributes_reduced_features (for use in Part Nos. 2 and 3)
Remove attributes in new products file
Since we removed the unwanted features in the known data file (existing products) we now need to do the same for the unknown data (new products) we will be using to make predictions.
In Weka
- Click: Open File
- Choose new_product_attributes.arff
- Click: Open
- Select Preprocess
- Place a check mark next to all the attributes except: Product #, 5 Star Reviews, 4 Star Reviews, Positive Service Review, and Negative Service Review, and Volume
- Click: Remove
- Click Save with the name new_product_attributes_reduced_features (for use in Nos. Part 2 and 3)
Summary
In this tutorial we learned how to preprocess a file in Weka using 3 different algorithms for feature selection. We learned how Weka guides us through the GUI by displaying an error message if we choose the wrong combinations. This is a welcome alternative to searching through log files. We then reduced the number of attributes by removing them using Weka, then stored the files for later use.
Resources
Ian Witten is the original author of the Weka software application. He has also authored a number of tutorials including: Data Mining with Weka, More Data Mining with Weka, and Advanced Data Mining with Weka. One such tutorial deals explicitly with attribute selection in Weka.
Ian also co-authored the well known book: Data Mining: Practical Machine Learning Tools and Techniques.
Jason Brownlee has created an excellent set of tutorials and one specifically called: An Introduction to Feature Selection.
Andrew Ng offers a visualization of feature reduction (aka Dimensionality Reduction) as well as an explanation of overfitting.