ML Tutorial: Weka Part 2 – Predictions with kNN

Getting started
K-Nearest Neighbors is one of the most basic algorithms in Machine Learning used for predictions. The number k defines how many data points (neighbors) are considered similar or alike.
In Part 1 above we used Weka to perform Feature Selection which included preprocessing the data using various filters to determine which attributes were most likely to impact sales volume. When we compared results across filters we found out of 18 attributes 4 were found to be the most important in determining sales volume.
How do we make predictions?
In this case, we decide to compare a new product (we have never sold before) to an existing product (one we have sales data for). If we can demonstrate enough similarity between these two, we may decide to assume the new product will sell just as well as the existing product.
One way to determine similarity is to determine the nearest neighbors to the new instance and assign a similar value to the new instance as that found in the neighborhood of similarity. We determine nearest using a distance calculation.
k-NN: Nearest Neighbor: Tuning the Algorithm
Once a machine algorithm like k-NN is chosen Weka can easily be used to tune its parameters for best results. In the k-NN algorithm Weka provides ready access to a variety of choices for: distance calculations, search algorithms, distance weighting, and the number (k) of neighbors among others.
Distance Calculation
In the nearest neighbor algorithm similarity is measured in distance. The closer two vectors (rows) are the more similar. There are various ways to measure distance. The Euclidean calculation measures distance through 3D space, Manhattan along the x and y axis. Weka performs these calculations quickly returning results we can easily compare and choose from.
Search Algorithm
To facilitate the distance calculation Weka must first organize the data into multidimensional space. Do do this Weka has multiple techniques: Ball Tree, Cover Tree, Filtered Neighbor Search, KD Tree, and Linear NN Search.
Distance Weighting
Once distance is calculated, a weighting algorithm can be applied in such a way as to give individual points various influence in affecting proximity. In Weka we will try both unweighted (d) and weighted (1/d) where impact is in inverse proportion to the distance. In the case of 1/d, the closer the distance the more impact it has in the calculation.
K: the number of neighbors used to predict
This number decides how many neighbors to be used in determining the classification (number of old products used to determine value of new product). If k=1, then the algorithm is simply called the nearest neighbor algorithm. If k > 1 a majority vote taken from those k’s in a particular neighborhood. The objective is to find the best k which is the k which produces the lowest error rate.
Cross Validation
If we used the test data (new products) to determine the best k we might end up with overfitting: giving us great results on this particular data set; but then not generalizing to new sets. Instead we set the actual test set (new products) aside until the very end and use 10 fold cross validation on the training set (existing products).
Let’s begin by running Weka’s IBk algorithm “out of the box” (using its default parameters) Notice we use the file from Weka Part 1. The set of data with the number of features reduced.
In Weka
- Select Explorer
- Click: Open File
- Choose existing product attributes_reduced_features.arff (from Part 1)
- Click: Open
- Click: Classify
- Under Classifier: Choose Lazy>IBk
- Click: Close
- Confirm Test Options: Cross Validation and Folds: 10
- Click Start
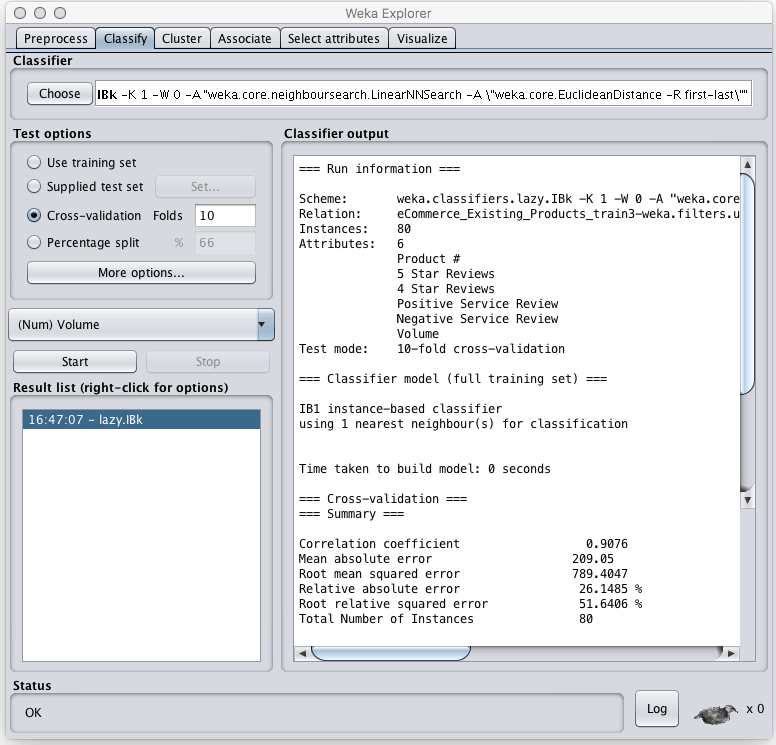
Default parameters and 10-fold cross-validation
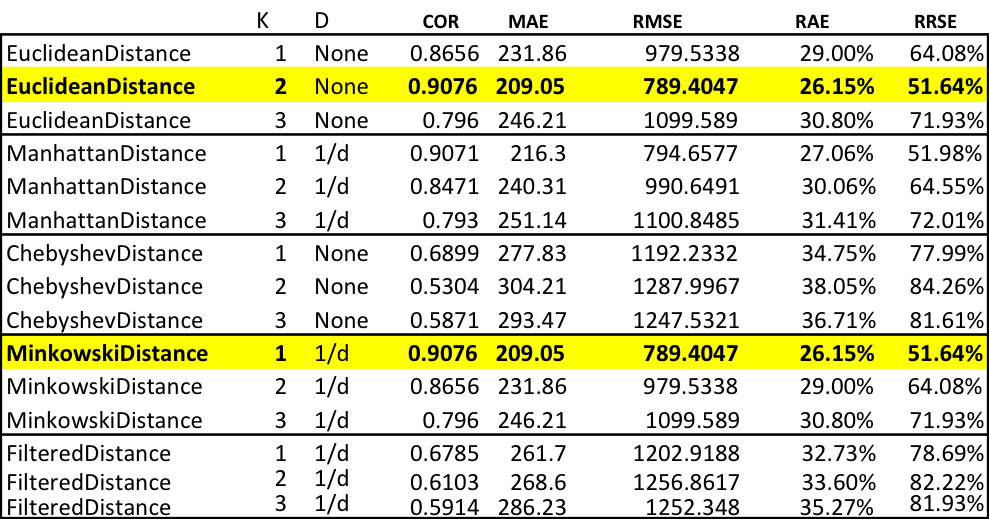
Using the default parameters for IBk we get an impressive 90.76% correlation. Lets change some of the parameters and see if we can get anything better.
Keeping the distance calculation as Manahattan: first change k until we see a decrease. Use the best k value and test three different distance weighting schemes: none, 1/d, 1-d. Use the best k and distance weighting values and test each of the five search algorithms in Weka.
In Weka
- Select Explorer
- Click: Open File
- Choose existing product attributes_reduced_features.arff (from Part 1)
- Click: Open
- Click: Classify
- Under Classifier: Choose Lazy>IBk
- Click: Close
- Left-click the text box to the right of the choose button
- Change KNN to 1
- Click the Choose button and select Ball Tree
- Left-click the text box to the right of the choose button
- Choose Manhattan
- Click OK
- Click OK
- Click Start
Below we capture the results for changing values of K, distance weighting and the neighborhood search algorithm.
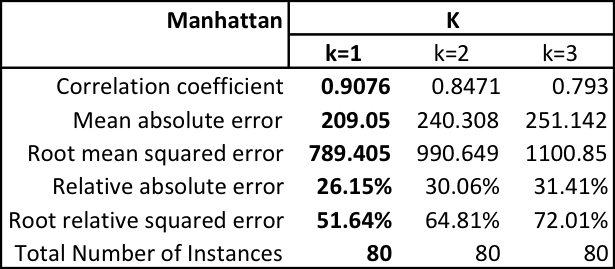
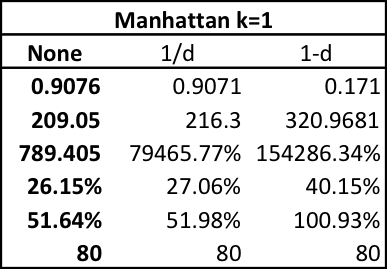
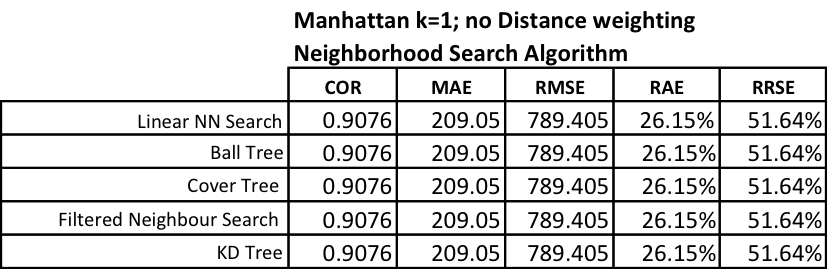
If we continue this pattern we can capture the same results for the Euclidean, Chebyshev, Minkowski, and Filtered distance calculations.
Saving the Tuned Model
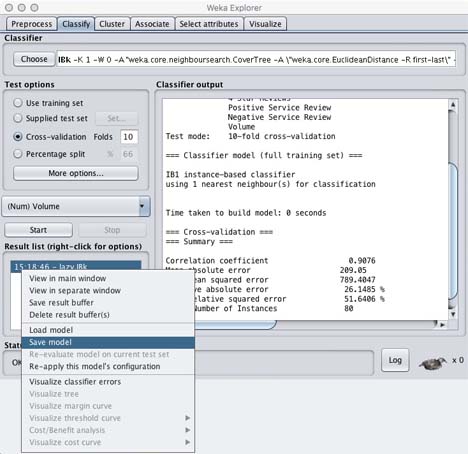
Once you have the model performing the way you want, it is sometimes a good idea to save it for later use.
In Weka
- With the model currently set to the best parameters
- Right-Click the results in the Result List
- Choose Save Model
- Provide a name (e.g. BestIBkEuclideanForNewProducts.model)
k-NN: Nearest Neighbor Prediction
We have tested a variety of tuning sets and found the two best configurations of Weka’s IBk using this data set. We will now preform the predictions using the best two sets of parameters.
First let’s confirm our settings for the first best IBk algorithm:
Euclidean distance calculation, k=2, and distance weighting=none. Since changing the neighborhood search algorithm did not have any impact we will keep Weka’s default.
In Weka
- Under Classifier: Choose Lazy>IBk
- Click: Close
- Left-click the text box to the right of the choose button
- Change KNN to 2
- Confirm the distance weighting is none
- Left-click the text box to the right of the choose button
- Choose Euclidean
- Click OK
- Click OK
- Click Start
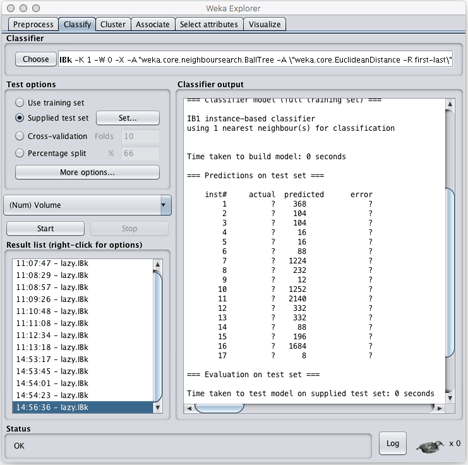
- Under Test Options: Choose Supplied Test Set
- Click Set
- Click Open file
- Choose new_product_attributes_reduced_features.arff (from Part 1)
- Click Close
- Click More options
- Under Output predictions click Choose
- Select Plain Text
- Click OK
- Click Start
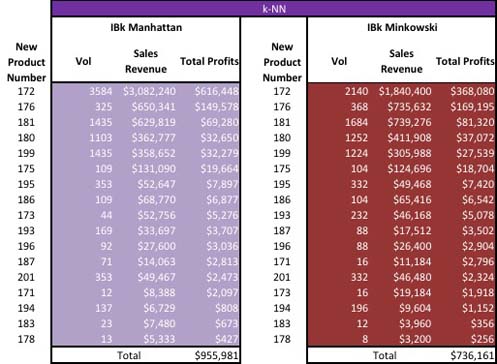
To run the second best tuning set confirm our settings for the IBk algorithm as: Minkowski distance calculation, k=1, and distance weighting=1/d. We can then resolve the instance with the new product number in the spreadsheet order the results by profits and present this to the business.
Summary
We began by testing a variety of parameters to tune each of 5 different distance implementations of the IBk algorithm in Weka. We captured values for the two best tuning parameter sets and ran those against our test set (new products). We got different values for all of the new products listed. However, if we ignore the actual values we find the top eight new products match in order of importance. In Weka Part 3 we will use an alternate predictive algorithm: SVM to perform the same predictions and compare results.
Resources
Saravanan Thirumuruganathan has a great page on K-Nearest Neighbor called A Detailed Introduction to K-Nearest Neighbor (KNN) Algorithm.
Although the code provided is for Python and R the explanation of K-Nearest Neighbor by Kevin Zakka may be worth a look. In it he provides a link to Scott Roe’s Blog post that provides an interactive animation that allows you to change the value for K and see the results of the boundary.
Ian Witten explains k-Nearest Neighbor with the assistance of Weka.